
|
|
^ Blog index << Broadcom VideoCoreIV 3D, budowa z perspektywy GPGPU >> Broadcom VideoCoreIV 3D, IDE i narzędzia
Broadcom VideoCoreIV 3D, podstawy programowania GPU
2017-12-29 Piotr Romaniuk, Ph.D.
Spis treści
Jak użyć GPU
Interfejsy do wymiany danych pomiędzy CPU i GPU
Użycie Vertex Pipe Memory, Vertex Cache Manager i DMA, VPM DMA Writer
Texture and Memory Loookup Unit
Jak uruchomić program na procesorze QPU
Links
Jak użyć GPU
W generalnym przypadku, większość reczy dzieje się na CPU, ponieważ jest to podstawowy procesor (host processor).
GPU odgrywa rolę procesora wspierającego, który posiada znaczącą moc obliczeniową.
W celu użycia GPU do obliczeń konieczne jest dostarczenie mu programu, który ma wykonywać oraz zapewnienie kanału komunikacyjnego. program and
Przez ten kanał odbywac się będzie wymiana danych pomiędzy tymi dwoma typami procesorów.
W przypadku Raspberry-Pi, kanał taki jest zrealizowany przez współdzieloną pamięć do której mają dostęp CPU i GPU.
Ten region pamięci znajduje się w pamięci video, który znajduje się w normalnej pamieci SDRAM ale jest zarezerwowany dla celów grafiki.
Rozmiar tej pamięci jest ustawiany w pliku konfigurqacyjnym (config.txt) przez określenie ograniczenia, które dzieli pamięć na przeznaczoną dla grafiki
i systemu operacyjnego.
W celu uruchomienia obliczeń na procesorze GPU (zawiera on wiele rdzeni QPU) nalezy wykonać nastepujące kroki
(rys. 1.):
- przydzielenie wspólnej pamięci do wymiany danych oraz na program dla QPU,
- skopiowanie programu dla rdzeni QPU do tej pamięci
- skopiowanie danych wejściowych
- wysłanie żądania do kolejki QPU Schedulera o uruchomienie programu na QPU
- oczekiwanie na zakończenie programów uruchomionych na rdzeniach QPU
- skopiowanie danych wynikowych zwróconych przez rdzenie QPU
- zwolnienie przydzielonej pamięci
Kroki [1] i [2] to inicjalizacja i muszą być wykonane jednorazowo na początku działania programu.
Program dla QPU należy przygotować wcześniej przez kompilację do kodu binarnego i włączenie takiej formy do aplikacji
(np. jako tabela binarnych warttości).
Kolejne kroki [3]-[6] mogą być powtarzane w pętli jeśli potrzebne jest wielokrotne uruchomienie programu GPU.
Zdarza się to często gdy dane są przetwarzane w częściach. Na samym końcu programu, tuz przed zakończeniem,
należy zwolnić przydzielone zasoby, głównie współdzieloną pamięć.
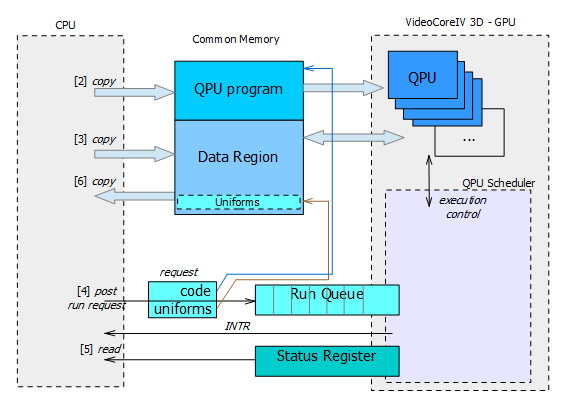
Rys. 1. Interakcje pomiędzy CPU i GPU (bezpośredni dostęp do kolejki uruchamiania QPU).
Pojedyncze żądanie uruchomienia QPU, które jest wstawiane do kolejki Schedulera QPU składa się tylko z dwóch elementów:
(a) adresu programu dla QPU
(b) adresu do tzw. uniforms.
Taki interfejs do QPU wydaje się być 'wąski' ale w istocie jest bardzo ogólny i uniwersalny.
W jęzuku wyższego poziomu odpowiada to określeniu wskaźnika do funkcji oraz wskaxnika do jej argumentów.
Uwaga: te adresy będą używane przez QPU, więc muszą posiadac wartości z przestrzeni adresowej QPU.
Ta przestrzeń jest inna niż ta używana przez CPU gdy odwołuje sie on do tej samej pamięci (np. kopiuje program dla QPU).
Z tego powodu, oprogramowanie musi zarządzań dwoma adresami dla tych wspólnych regionów. Nie jest to bardzo kłopotliwe, bo różnią się one jedynie
adresem bazowym.
Adres [a] jest używany przez scheduler do ustawienia rejestru PC w QPU gdy ten jest uruchamiany.
Uwaga: oprogramowanie nie ma kontroli nad tym gdzie będzie znajdował się blok pamieci współdzielonej,
nie może uzyskać pamięci o okreslonym z góry ustalonym adresie.
Wysyła ono żądanie do systemu o przydzielenie pewnego rozmiaru pamięci określonego typu.
Wynikają z tego dwie rzeczy: (1) program QPU musi być relokowalny, (2) położenie regionu danych jest dynamiczne,
więc jego adres musi też być przekazany do QPU.
Adres [b] wskazuje na uniforms. Znaczeniowo uniforms są argumentami programu dla QPU.
W przypadku VideoCoreIV 3D, uniforms sa reprezentowane przez tabele wartości 32-bitowych.
QPU ma dostęp sekwencyjny do tej tabeli i czyta z niej przez wielokrotny odczyt jednego, specjalnego rejestru przeznaczonego do tego celu.
Wartości zapisane w uniforms mogą mieć dowolny format:
32-bitowy parametr całkowity, cztery 8‑bitowe wartości upakowane w 32-bitowym słowie, wartość zmiennoprzecinkowa typu float,
wskaźnik, itp.
Znaczenie wartości z uniforms zależy od wyboru programisty. Zwykle jest ono zapisane na stałe w aplikacji i programie QPU.
Oczywiście musi ona być zgodna na obu końcach.
Uniforms są też wygodna metodą do rozróżnienia rdzeni QPU pomiędzy sobą. Ponieważ uniforms są określane na każdy QPU osobno,
to wystarczy wstawić w nie numer qpu. To rozróżnienie jest istotne gdyż często rdzenie QPU wykonują ten sam program,
ale mają przetwarzać inną cześć danych wejściowych (w ten sposób realizuje się równoległe obliczenia).
Interfejsy do wymiany danych pomiędzy CPU i GPU
Broadcom VideoCoreIV 3D posiada trzy sposoby przekazywnaia danych z CPU:
- uniforms (tylko odczyt przez QPU w spoób sekwencyjny),
- jednostka Texture and Memory Lookup Unit (tylko odczyt przez QPU)
- pamięć Vertex Pipe Memory wymieniana przez DMA (odczyt i zapis)
Uniforms są wygodnym sposobem na przekazanie argumentów i niewielkiej ilości danych (np. jakiejś konfiguracji,
parametrów algorytmu, lokalizacji danych w pamięci, liczby qpu, itp.)
Dostęp do uniforms jest sekwencyjny i polega nie powtarzaniu odczytu jedengo rejestru - unif (zobacz pzykład poniżej na rys. 2).
Aplikacja jest odpowiedzialna za przygotowanie właściwego obrazu tabeli uniforms (kolejności wpisów oraz typów).
Format uniforms jest zwykle ustalony na stałe (hardcoded) i specyficzny dla konkretnych programów QPU.
Jeśli znajdują sie tam wskaźniki muszą one być określone w przestrzeni adresowej QPU.
mov r_filter, unif # odczyt adresu danych filtru
mov r_qpu_number, unif # odczyt ilości używanych QPU
mov r_qpu_id, unif # odczyt numeru QPU (QPUid)
mov r_counter, unif # odczyt ilości bloków danych wejściowych
mov r_in_data, unif # odczyt adresu danych wejściowych
mov r_out_data, unif # odczyt adresu bufora na dane wyjściowe
Rys. 2. Przykład użycia uniforms.
Jednostka Texture and Memory Lookup Unit dobrze nadaje się do odczytu swobodnego danych albo takich,
które są traktowane jako indeksowana tabela a jej elementy wybiera się po indeksie.
Pamięć Vertex Pipe Memory jest pamięcią lokalną, wspólną dla wszystkich QPU. Jej treśc może być ładowana lub zapisywana
z pamięci wspólnej przez DMA.
Z perspektywy QPU ta pamięć może byc odczytywana i zapisywana, więc może być użyta zarówno jako dane wejściowe jak i wyjściowe
Pamięc może wymieniać większe części danych.
Użycie Vertex Pipe Memory, Vertex Cache Manager and DMA, VPM DMA Writer
Vertex Pipe Memory (VPM) jest typem lokalnej pamięci, wspólnej dla wszystkich rdzeni QPU.
Jest ona zorganizowana w dwuwymiarową tabelę: 64 rzędy x 16 kolumn zawierających 32-bitowe wartości (calkowity rozmiar 4KB).
Ta pamięć jest dobrze przystosowana do przetwarzania obrazów, gdzie dane są zorganizowane w linie.
Mozliwy jest dostęp do rozproszonych danych, w organziacji pionowej lub poziomej, elementy mogą być nawet upakowane w 32-bitowych słowach.
Ponadto, jest konfigurowalna autoinkrementacja (zobacz pojęcie strade w dokumentacji układu).
Dane wejsciowe są ładowane do VPM przez inny moduł sprzętowy - Vertex Cache Manager & DMA (VCM & VCD).
Po załadowaniu rdzeń QPU może odczytywać dane z pamięci VPM, przetwarzać i zapisywac z powrotem do VPM.
Należy zwrócić uwagę, że rdzeń QPU wykonuej te operacje jako SIMD16.
Po zakończeniu przetwarzania bloku danych, zawartość pamięci VPM jest zapisywana do pamięci współdzieonej z CPU przez VPM DMA Writer (VDW). Wszystkie moduły, które uczestniczą w przesłaniach DMA danych do i z VPM mogą być rozumaine jako jedna wirtualna jednostka (dalej określana jako VCD).
Takie podejście jest użyteczne podczas konfiguracji i użycia, które są opisane poniżej.
Dwa interfejsy VPM z obu końców: do rdzeni QPU oraz do pamięci współdzielonej, są oddzielni konfigurowane. Ta konfiguracja
jest przeprowadzana przez QPU ale jest ona trochę niejasna.
Stało się tak dlatego, że konfiguracja odbywa się poprzez zapis wartości jedynie do dóch rejestrów z przestrzeni adresowej QPU.
Gdy konfiguruje się odczyt albo zapis, rejestry ra49 lub rb49 muszą być odpowiednio zapisywane.
Bit 31 zapisywanej wartości decyduje o tym, który interfejs jest konfigurowany (VCD/VPM), a pozostałe bity
zawierają wartości konfiguroanych pól (zobacz tabele poniżej).
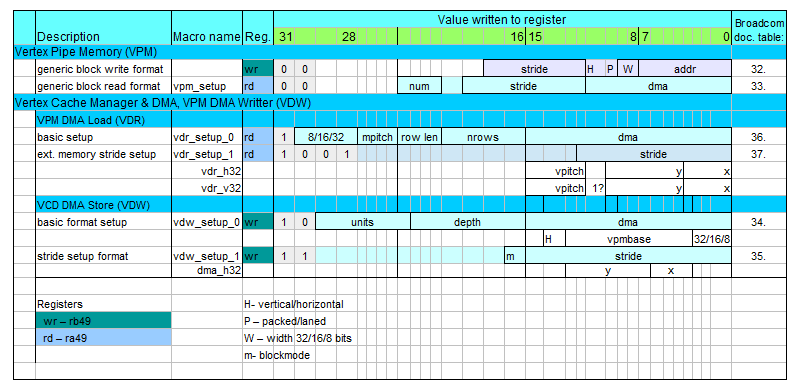
Figure 3. Rejestry i makra do konfiguracji VPM i VCD.
Ostatnia kolumna tabeli wskazuje numery tabel w dokumenacji producenta z dokładnym opisem pól rejestrów.
Dla programisty wykonanie konfiguracji jest znacznie łatwiejsze gdy korzysta się z gotowych makr niż wyznacza wartości na podstawie dokumentcji.
Nazwy tych makr są również umieszczone w powyższej tabeli a ich kod znajduje się w przykładzie programowania QPU - hello_fft (zobacz linki na dole tej strony).
Oprócz konfiguacji do pracy z VCD niezbędne są jeszcze dwa elementy. Pierwszy to ustalenie adresu gdzie/skąd dane mają być zapisane.
Do tego celu używane są rejestry ra50 (vpm_add_ld) oraz rb50 (vpm_add_st).
Zapis do tych rejestrów prowadzi do wyzwolenia transferu DMA, więc musi być on wykonywany na końcu po suatwieniu wszystkiego.
Drugim elementem jest synchronizacja - QPU musi być powiadomiony kiedy skończy się transfer dma, w przeciwnym przypadku
mogłby odczytywać z VPM miejsce gdzie dane nie zostały jeszze załadowane w całości, lub nadpisać dane, które nie zostały jeszcze
wypchnięte do pamięci wspóldzielonej. Odczyt rejestrów ra50 (vpm_wait_ld) lub rb50 (vpm_wait_st) wstrzymuje rdzeń QPU do czasu
zakończenia transferu.
mov vw_setup, vdw_setup_0(64, 16, dma_h32( 0,0)) # ustawie konfiguracji zapisu DMA (VPM->SDRAM przez VCM&VCD)
mov vw_setup, vdw_setup_1(0) # ustawienie extra stride=0
mov vw_addr, dbg_rfile_dump # zapis adresu docelowego i uruchomienie transferu dma
mov -, vw_wait # oczekiwanie na zakończenie transferu
Rys. 4. Przykład zapisu VCD (vw_setup, vw_addr,
vw_wait są rejestrami QPU z blisko powiązanego hardware'u).
Texture and Memory Loookup Unit (TMU)
TMU zostało zaprojektowane do wykonywania mapowania tekstur. Z perspektywy QPU ta jednostka pozwala jedynie na odczyt (nie
można przez nia nic zapisać do pamięci) - może więc służyć jako odczyt danych wejściowych.
Niemniej jednak, TMU jest niezwykle uzyteczne dla programowania GPGPU. Ta jednostka umożliwia wybiórczy odczyt danych, gdzie
sa one wybierane indeksami. Podobnie jak rdzeń QPU, jednostka TMU pracuje z danymi SIMD16, więc może odczytać 16 elementów na raz.
W celu odczytu wektora 16 elementów (zobacz przykład poniżej) wybrany rejestr powinien być zapisany 16 wartościami indeksów danych,
które chce sie pobrać. Następnie należy pomnożyć te indeksy przez 4 i a potem otrzymany wektor dodać do wartości adresu bazowego
tabeli. Otrzymana wartość powinna być zapisana do rejestru tmu#_s. W kolejnej instrukcji należy zasygnalizować TMU
konieczność odczytu danych, w wyniku czego TMU odczyta dane i umieści wynik w akumulatorze r4, skąd można je pobrać do dowolnego rejestru.
1 add t0s, r_base_addr, r_indexes # obliczenie adresu i zapis do tmu#_s
2 ldtmu0 # sygnalizacja TMU aby odczytał dane
3 mov r_dst, r4 # odczytanie danych z r4
Rys. 5. Przykład odczytu z TMU.
Uwaga:
gdy elementy zawierają dokladne wartości indeksów, tzn. bez mnożenia x4, TMU załaduje do kolejnych
czterech elementów tę samą wartość odpowiadającą wyrównanemu adresowi. To może być użyteczne do zwielokrotnienia
danych wejściowych w quadzie zamaist odczytu do kolejnych elementów.
Dla każdego slice'a są dwa TMU: tmu0 and tmu1. Są one współdzielone pomiędzy cztery rdzenie QPU znajdujące sie w tym slice'ie
(see VideoCoreIV 3D architecture), na szczęście każdy rdzeń ma odpowiadającą mu
kolejkę zbierającą jego żądania dla TMU.
Chociaż wg dokumentacji kolejki te mają pojemność na 8 elementów gdy używa się odwołań tylko ze współrzędną s (zwiazek z teksturą),
to tylko 4 są godne zaufania - zaobserwował to Marcel Muller.
Jednostki TMU są wyposażone w pamięć podręczna (cache) o wielkości 4KB i organizacji w 64 bajtowe linie.
Używane jest 10 najmłodszych bitów adresu.
Jak uruchomić program na procesorze QPU
Przykład programowania QPU hello_fft przedstawia dwie metody uruchamiania programów na QPU:
- poprzez sterownik VCIO, który opakowuje dostep do mailboxa
- poprzez bezpośredni dostęp do kolejki scheulera QPU.
Obie metody wymagają użycia sterownika VCIO, z którym aplikacja może się komunikowac przez urządzenie znakowe /dev/vcio,
wysyłając wiadomości przez funkcję ioctl(). Sterownik alokuje współdzieloną pamięć, o której była mowa na początku tej strony.
Może być on też pomocny w uruchamianiu programów QPU. W celu poznania więcej szczegółów nalezy zapoznać się z plikiem mailbox.c z przykładu.
Przykład hello_fft używa dwóch metod do uruchamiania prorgamu QPU, wybierając odpowiednią na podstawie oczekiwanego
czasu obliczeń. Gdy czas ten jest krótszy niż ustalony próg, wybierana jest metoda bezpośrednia, w przeciwnym przypadku
wysyłane jest zlecenie prze mailbox.
Na tej podstawie mozna wywnioskować, że metoda z mailboxem posiada jakieś dodatkowe obciążenie, niezbęde np. do przelączenia
kontekstu na kernel, i inne czynności pośredniczące.
Metoda bezpośrednia polega na dostępie do kolejki schedulera QPU poprzez zapisy dwówch rejestrów:
V3D_SRQUA - adres tabeli uniforms,
V3D_SRQPC - adres programu dla rdzenia QPU (musi być zapisane po zapisie odpowiadającego adresu tabeli uniforms).
Należy zapewnić aby te adresy były adresami z przestrzeni adresowej QPU.
Powyższe dwa zapisy należy powtórzyć dla każdej instancji programu QPU.
Zakończenie wszystkich programów moze być wykryte przez sprawdzania pola QPURQCC w rejestrze V3D_SRQCS,
gdzie znajduje się kumulacyjna liczba zakończonych programów.
Licznik ten może być skasowany przed zgłoszeniem pierwszego żadania uruchomienia programu.
Użycie tej metody często wiąże się z oczekiwaniem blokującym w programie (busy waiting).
Linki
[1] Broadcom VideoCore IV 3D, Architecture Reference Guide - dokumentacja VideoCore producenta układu
[2] Dodatek do dokumentacji Broadcom VideoCore IV, Marcel Muller
[3] Przykład programowania QPU - hello_fft
https://github.com/raspberrypi/firmware/tree/master/opt/vc/src/hello_pi/hello_fft
Jest to też umieszczone w gotowych obrazach Raspbiana w /opt/vc/src/hello_pi/hello_fft.
|

|
