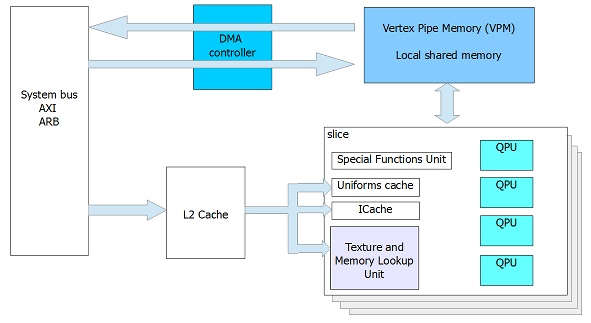
QPU Registers
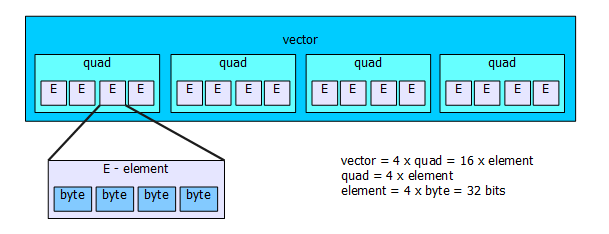
QPU constains a few accumulators and two large files of registers. Each register can keep the vector of elements, so is adapted to SIMD operations.
There are 4 accumulators available for general use and 2 special function one.
There are 32 registers in each register file, and files are designated by file-A and file-B. All registers in these two files form
a local memory that is available per each QPU.
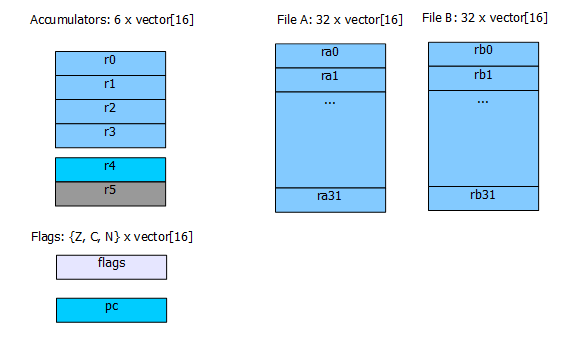
Figure 4. Registers of QPU.
Accumulators and registers from the files differ by:
- lenght of a data path in QPU pipeline, hence for accumulators result is available for next instruction,
- flexibility in access in one instruction - there are some constraints on using registers from files
- vector element rotation can be only performed on accumulators
- number of accumulators is small
Because of these properties file registers are good for storing variables and configurations for further use, while accumulators should be heavily
used in calculations. When the result is obtained it can be stored in the file register. One can tell that the accumulators hold partial results and
the file registers have assigned meaning for whole program (like global variables in higher level programming language).
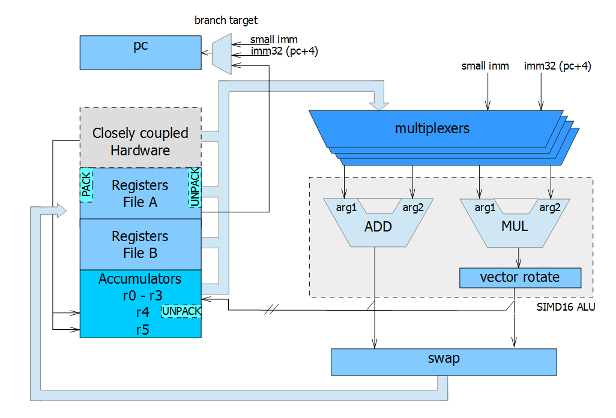
Closely Coupled Hardware
QPU can control hardware that is around it (like: Vertex Pipe Memory, DMA, Texture and Memory Lookup Unit, Special Functions Unit, etc.). These units are
accesible via address space of the register files (addresses over 31 are used for this purpose). They act like registers, so regular instructions can operate
on them.
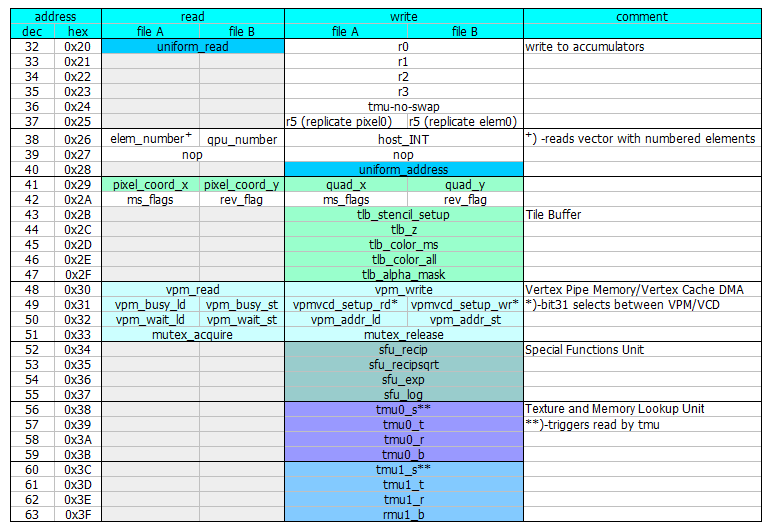
Figure 5. Address space used for access to closely coupled hardware.
QPU Instructions
QPU has 64-bit instruction format (each instruction has this size). There is small number of instruction types but due to size of the processor word they
are flexible. The types of instructions are:
- ALU instructions,
- load instructions
- branch instructions
- synchronization instructions (semaphores)
Instructions control the dual-issue ALU that can execute two operations in parallel. One path is responsible for addition operation,
while in second one multiplication and vector rotation are performed.
The processor has an instruction pipeline, that is not flushed when branch is executed, hence in examplar source code a strange sequence of
instructions can be found. After branch instruction there are three extra, unexpected lines:
1 :entry
2 brr -, r:loop1
3 nop ; ldtmu0
4 mov r0, r4 ; ldtmu0
5 mov r1,r4
It means that these three lines (3,4,5) will be executed after branch is taken but before first instruction at the branch target. This happens
because they remains in the pipeline when branch is executed.
Details of QPU instructions can be found in VideoCore IV 3D manufacturer's documentation (see (1) in links below). Be sure to read addendum (see (2) in links below)
where Marcel Muller, the author of videocore macroassembler explains some specific details of instructions, issues and undocumented features.
Main limitations of instructions
Due to the QPU architecture following limitations may be observed:
- the result written into file register is not available for next instruction,
- one instruction cannot use more than one argument from the same register file
- small immediate cannot be used together with register from file B
- vector rotation must be performed on accumulator
- the accumulator that is rotation performed on must not be written in previous instruction
- packed formats are supported only by registers from file A and accumulator r4
- there is no hadware stack, selected file register should be used as link register (like in ARM architecture)
- if results from two parts of ALU (add and mul) are both file registers, they should be in different files